Methodology
Introduction
The DRRP facilitates research into the personal and professional trajectories and textual and visual practices of dragomans (diplomatic translator-interpreters) employed by the Venetian bailate (permanent residency) in the Ottoman capital and beyond. The platform offers a range of data sets related to dragomans’ activities that can be dynamically edited, analyzed, and augmented, modeling collaboration and resource sharing among scholars and students from a range of disciplinary perspectives interested in processes of cultural mediation in the early modern Mediterranean. Future updates to the platform will expand both the range of data sets and the analytical tools available for their analysis.
Underlying the project is the photography of archival documents from multiple archives. These “digital surrogates” facilitate data-driven insights and wider perspectives on the historical record. They can be robustly re-contextualized using metadata that describes complex facets and interrelationships of people, documents, events, archival practices, and secondary literatures, facilitating advanced querying, natural language processing, and visualization.
The project takes cues from a moment when many scholars seek open, transparent, and collaborative approach to understanding and communicating information about the past, and nurtures interdisciplinary teams that include experts and emerging scholars in history, information science, and computer science. A recent SSHRC Insight Grant (Trans-Imperial Archives: Diplomacy, Circulation, and Entanglement in the Early Modern Mediterranean) has funded both annual research assistantships for participating graduate students and postdoctoral researchers and shorter-term co-op placements for undergraduate students. It has also supported ongoing communication about the project’s outcomes and methodologies through publications and conference presentations. Ultimately, the project seeks to communicate models that could be used by other research groups facing similar challenges in disambiguating complex materials and expanding the scope and frames of reference for historical and multidisciplinary study.
Data Model
The process of structuring and cataloging provides an entry way into better understanding the relationships that emerge between artifacts (archival units of various size and type), the textual records they contain (documents), the persons responsible for their production (official authors, secretaries, scribes, translators) or who are mentioned in them (addressees, other office holders), and the terms used to describe any of these relationships. A high level description of the data model is presented in Figure 1.
Figure 1: High Level Data Model
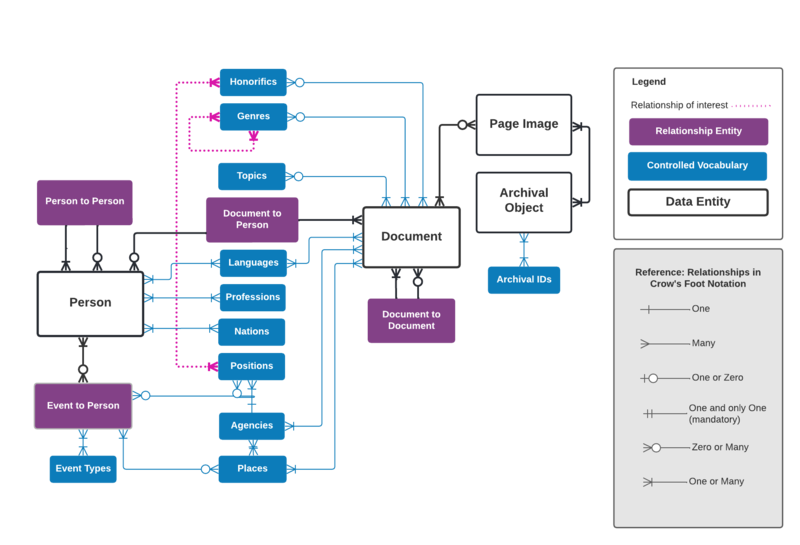
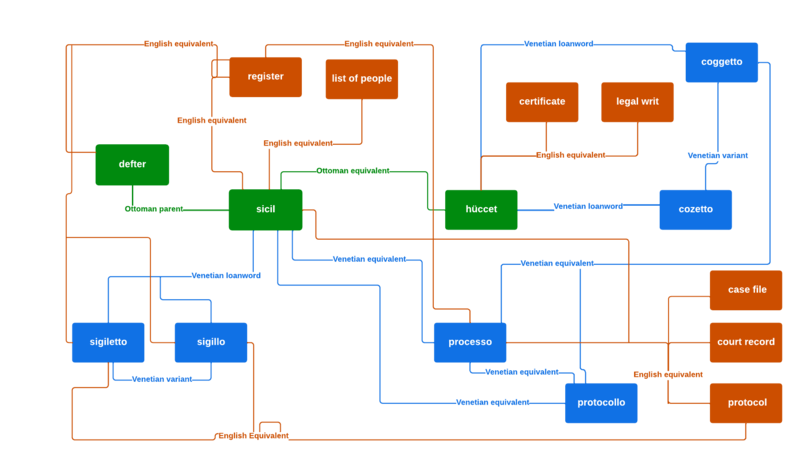
By recording instances of specific genre, honorific, position, and agency terms appearing in primary documents and in relevant secondary literature and by indexing and visualizing these instances, we can better understand these terms’ range, frequency, and temporally-, spatially-, and institutionally-shifting contexts of use (see Figure 2).
Figure 2: Term relationships
The project’s core metadata has been sourced and described in multiple systems over the years, from bibliographic software-driven description (in systems like Procite, Endnote, and Zotero) to MODS and MADS-governed descriptive XML metadata documents, to flat-file databases. Data has been migrated and reshaped using python scripting, XSLTS, Open Refine, and Google Sheets. Records have been created in Islandora-based systems and indexed in Solr and linked-data triple stores to support data querying, and are being analyzed using natural language processing (NLP) techniques. Other software tools such as Gramps and Palladio have supported visualization and analysis on the evolving project dataset, as has Sparql based querying of a linked-data triplestore.
The text mining process leverages our evolving data model to study variations in dragomans’ translation practices over time, across genres, and between individual translators. In the future we may also correlate these variations with other variables. As our first experiment in NLP, we used several Python libraries (incl. Pandas, regular expressions, match, math and repeat) to identify all chancery genre terms in the corpus. This involved, first, retrieving all the possible orthographical variations (alternate spellings and contractions) of each genre term across the corpus (while excluding false matches, ie closely related lexemes that are not genre terms) and, second, counting the number of unique documents in the corpus in which each specific genre term (in all its variations) appears. The quantitative output generated through these processes then serves as the basis for visualizations using Google Looker Studio. An example is provided in Figure 3.
Figure 3: Genre Frequency in the Carte turche, 1589-1682
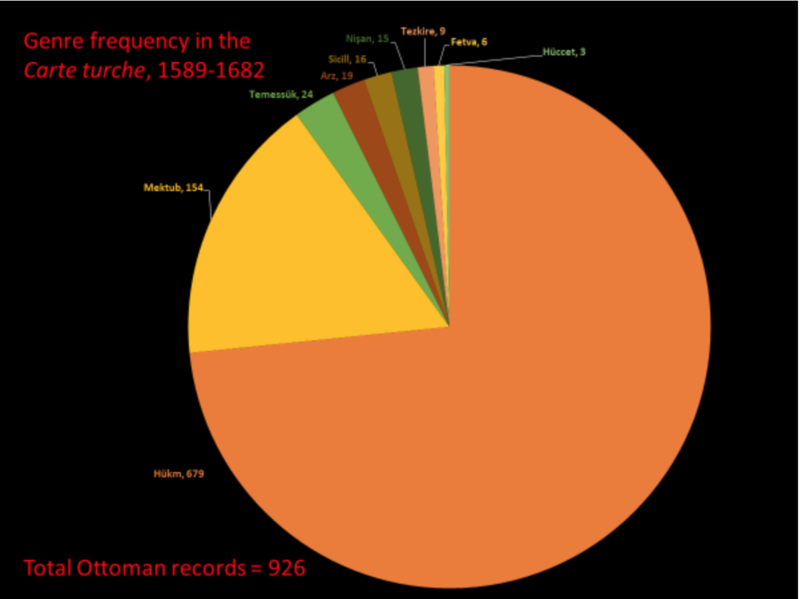
Based on this preliminary data, we then further explore specific hypotheses, for example about the correlation between specific Italian glosses for Ottoman genre terms (e.g. the alternate Italian glosses for the Ottoman term hatt-ı şerîf, rendered in the Italian corpus variably as “Sublime commandamento,” “Commandamento reggio,” or “Comamndamento imperiale”) and individual translators, sociological groupings of translators (experienced dragomans vs novice apprentices), or changes over time in putative translation stylesheets. Another output of the initial model for genre terms is the ability to identify “edge cases,” ie documents that do not follow a common pattern of collocation between specific genre terms that generally appear together, such as “arz,” “commandamento,” and “segno.”
Due to the complexity of the dataset, which is characterized by its size and the presence of numerous symbols and characters, the mining process has been supported by SciNet, the advanced research computing services at the University of Toronto.
Geographic Information Systems (GIS)
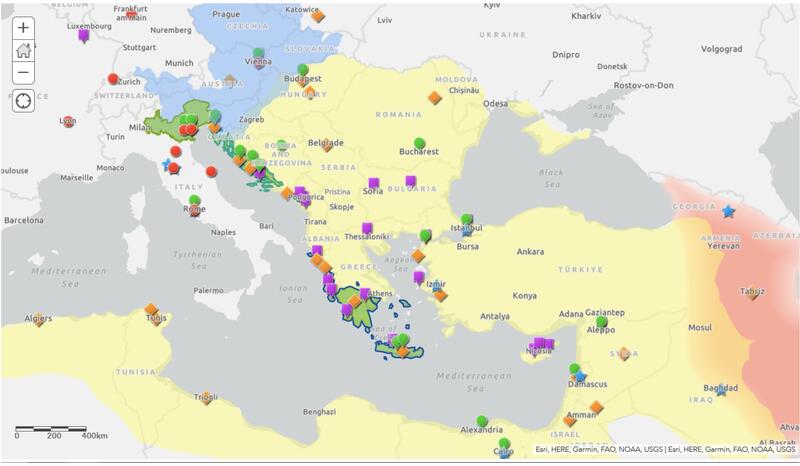
With the assistance of Nick Field and the Map and Data Library, the project, using ArcGIS Online, has sought to visualize circulatory regimes. By taking the rich data collected by the project and drawing out relevant geographic information like Dragoman places of birth, work, and travel, and the locations where translations of Ottoman works were authored and published we have created maps that display the spatial and temporal dynamics of the circulatory regimes of Mediterranean diplomatic chancelleries. By overlaying this information with the historic boundaries of the Venetian, Ottoman, and Austrian empires, the trans-imperial nature of these networks can be further highlighted. See Figure 4 for an example of one such map.
Figure 4: ArcGIS generated map depicting circulatory regimes of Mediterranean diplomatic chancelleries
Core Methodological Tools
- A data dictionary including a set of controlled vocabularies
- A preliminary ontology (formal description of logic) that supports data modeling from multi-lingual archives across multiple jurisdictions
- A metadata-application powered by Apache Lucene/Apache Solr for interface-based querying in a Drupal Interface
- A triplestore (Blazegraph) with an endpoint supporting sparql querying of the project’s underlying linked data
Future Directions
We are currently planning interface affordances that will allow for the existing data set to grow and expand to accommodate more documentary evidence from the period and allow historians, philologists, codicologists, and translation studies scholars to continuously refine their analyses of records and their interrelationships, unlocking the power of shared datasets on the region and its history. Data and media assets (images) for the project are held in an Islandora repository. ARK Identifiers also support long-term preservation through features such as checksum monitoring.